调用第三方进行子域名查询
- 发表于
- 安全工具
因为最近都是使用的是subDomainsBrute.py对子域名进行爆破。但是三级域名的支持却不是很好。有小伙伴提示是在http://i.links.cn/subdomain/上进行查询的。于是简单的测试了下,写了一个小脚本方便查询
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #! /usr/bin/env python # -*- coding: utf-8 -*- import requests,re,sys def get_domain(domain): headers = { "Content-Type": "application/x-www-form-urlencoded", "Referer": "http://i.links.cn/subdomain/", } payload = ("domain={domain}&b2=1&b3=1&b4=1".format(domain=domain)) r = requests.post("http://i.links.cn/subdomain/", params=payload) file=r.text.encode('ISO-8859-1') regex = re.compile('value="(.+?)"><input') result=regex.findall(file) list = '\n'.join(result) print list if __name__ == "__main__": commandargs = sys.argv[1:] args = "".join(commandargs) get_domain(args) |
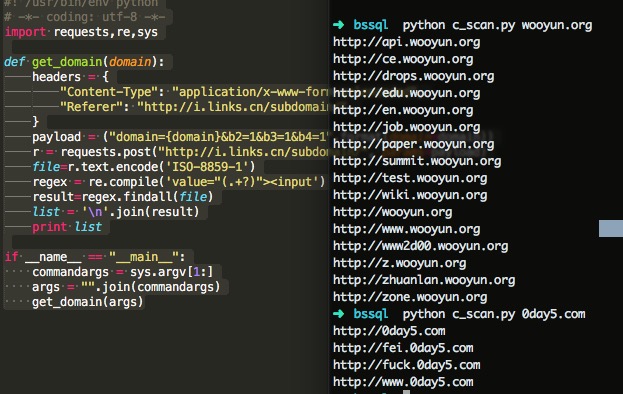
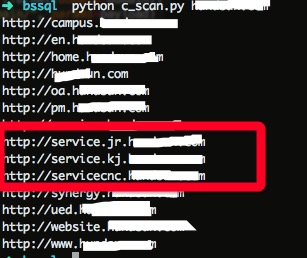
对比了下。还真的处了三级域名
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 | #!/usr/bin/env python # encoding: utf-8 import re import sys import json import time import socket import random import urllib import urllib2 from bs4 import BeautifulSoup # 随机AGENT USER_AGENTS = [ "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)", ] def random_useragent(): return random.choice(USER_AGENTS) def getUrlRespHtml(url): respHtml='' try: heads = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Charset':'GB2312,utf-8;q=0.7,*;q=0.7', 'Accept-Language':'zh-cn,zh;q=0.5', 'Cache-Control':'max-age=0', 'Connection':'keep-alive', 'Keep-Alive':'115', 'User-Agent':random_useragent()} opener = urllib2.build_opener(urllib2.HTTPCookieProcessor()) urllib2.install_opener(opener) req = urllib2.Request(url) opener.addheaders = heads.items() respHtml = opener.open(req).read() except Exception: pass return respHtml def links_get(domain): trytime = 0 #links里面得到的数据不是很全,准确率没法保证 domainslinks = [] try: req=urllib2.Request('http://i.links.cn/subdomain/?b2=1&b3=1&b4=1&domain='+domain) req.add_header('User-Agent',random_useragent()) res=urllib2.urlopen(req, timeout = 30) src=res.read() TempD = re.findall('value="http.*?">',src,re.S) for item in TempD: item = item[item.find('//')+2:-2] #result=socket.getaddrinfo(item,None) #print result[0][4] domainslinks.append(item) domainslinks={}.fromkeys(domainslinks).keys() return domainslinks except Exception, e: pass trytime += 1 if trytime > 3: return domainslinks def bing_get(domain): trytime = 0 f = 1 domainsbing = [] #bing里面获取的数据不是很完全 while True: try: req=urllib2.Request('http://cn.bing.com/search?count=50&q=site:'+domain+'&first='+str(f)) req.add_header('User-Agent',random_useragent()) res=urllib2.urlopen(req, timeout = 30) src=res.read() TempD=re.findall('<cite>(.*?)<\/cite>',src) for item in TempD: item=item.split('<strong>')[0] item += domain try: if not (item.startswith('http://') or item.startswith('https://')): item = "http://" + item proto, rest = urllib2.splittype(item) host, rest = urllib2.splithost(rest) host, port = urllib2.splitport(host) if port == None: item = host else: item = host + ":" + port except: print traceback.format_exc() pass domainsbing.append(item) if f<500 and re.search('class="sb_pagN"',src) is not None: f = int(f)+50 else: subdomainbing={}.fromkeys(domainsbing).keys() return subdomainbing break except Exception, e: pass trytime+=1 if trytime>3: return domainsbing def google_get(domain): trytime = 0 s=1 domainsgoogle=[] #需要绑定google的hosts while True: try: req=urllib2.Request('http://ajax.googleapis.com/ajax/services/search/web?v=1.0&q=site:'+domain+'&rsz=8&start='+str(s)) req.add_header('User-Agent',random_useragent()) res=urllib2.urlopen(req, timeout = 30) src=res.read() results = json.loads(src) TempD = results['responseData']['results'] for item in TempD: item=item['visibleUrl'] item=item.encode('utf-8') domainsgoogle.append(item) s = int(s)+8 except Exception, e: trytime += 1 if trytime >= 3: domainsgoogle={}.fromkeys(domainsgoogle).keys() return domainsgoogle def Baidu_get(domain): domainsbaidu=[] try: pg = 10 for x in xrange(1,pg): rn=50 pn=(x-1)*rn url = 'http://www.baidu.com/baidu?cl=3&tn=baidutop10&wd=site:'+domain.strip()+'&rn='+str(rn)+'&pn='+str(pn) src=getUrlRespHtml(url) soup = BeautifulSoup(src) html=soup.find('div', id="content_left") if html: html_doc=html.find_all('h3',class_="t") if html_doc: for doc in html_doc: href=doc.find('a') link=href.get('href') #需要第二次请求,从302里面获取到跳转的地址[速度很慢] rurl=urllib.unquote(urllib2.urlopen(link.strip()).geturl()).strip() reg='http:\/\/[^\.]+'+'.'+domain match_url = re.search(reg,rurl) if match_url: item=match_url.group(0).replace('http://','') domainsbaidu.append(item) except Exception, e: pass domainsbaidu={}.fromkeys(domainsbaidu).keys() return domainsbaidu def get_360(domain): #从360获取的数据一般都是网站管理员自己添加的,所以准备率比较高。 domains360=[] try: url = 'http://webscan.360.cn/sub/index/?url='+domain.strip() src=getUrlRespHtml(url) item = re.findall(r'\)">(.*?)</strong>',src) if len(item)>0: for i in xrange(1,len(item)): domains360.append(item[i]) else: item = '' domains360.append(item) except Exception, e: pass domains360={}.fromkeys(domains360).keys() return domains360 def get_subdomain_run(domain): mydomains = [] mydomains.extend(links_get(domain)) mydomains.extend(bing_get(domain)) mydomains.extend(Baidu_get(domain)) mydomains.extend(google_get(domain)) mydomains.extend(get_360(domain)) mydomains = list(set(mydomains)) return mydomains if __name__ == "__main__": if len(sys.argv) == 2: print get_subdomain_run(sys.argv[1]) sys.exit(0) else: print ("usage: %s domain" % sys.argv[0]) sys.exit(-1) |
使用
| 1 | python mysubdomain.py youdomain.com |
2016.1.28增加百度与360搜索抓取
原文连接:调用第三方进行子域名查询 所有媒体,可在保留署名、
原文连接
的情况下转载,若非则不得使用我方内容。