C-Eval:热门AI 语言模型的中文水平能力测试
- 发表于
- 人工智能
热门AI 语言模型的中文水平能力排行榜
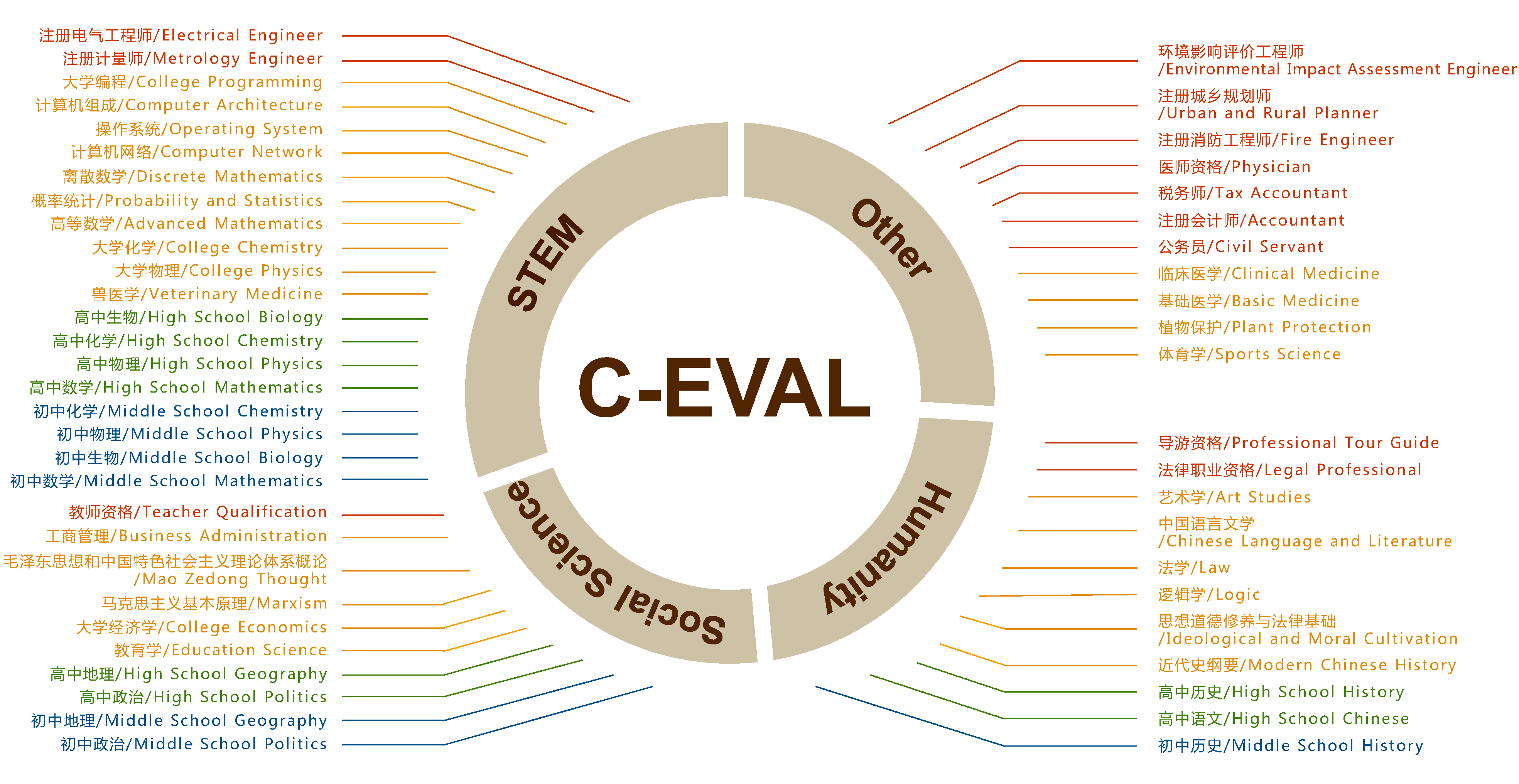
你知道当前 AI 语言模型在中文中能力水平如何吗?很多项目在基于中文做应用级的AI项目,C-Eval是一个全面的中文基础模型评估套件,包含了 13948 个多项选择题,涵盖了 52 个不同的学科和四个难度级别,对当前常见模型进行了一个全面准确的排名,有兴趣可以瞧瞧。
| # | 模型名称 | 发布机构 | 测试时间 | 平均 | 平均(Hard) | STEM | 社会科学 | 人文科学 | 其他 |
| 0 | GPT-4 | OpenAI | 2023/5/15 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| 1 | ChatGPT | OpenAI | 2023/5/15 | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| 2 | Claude-v1.3 | Anthropic | 2023/5/15 | 54.2 | 39 | 51.9 | 61.7 | 52.1 | 53.7 |
| 3 | Claude-instant-v1.0 | Anthropic | 2023/5/15 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| 4 | GLM-130B | Tsinghua | 2023/5/15 | 40.3 | 30.3 | 34.8 | 48.7 | 43.3 | 39.8 |
| 5 | Bloomz-mt | BigScience | 2023/5/15 | 39 | 30.4 | 35.3 | 45.1 | 40.5 | 38.5 |
| 6 | LLaMA-65B | Meta | 2023/5/15 | 38.8 | 31.7 | 37.8 | 45.6 | 36.1 | 37.1 |
| 7 | ChatGLM-6B | Tsinghua | 2023/5/15 | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| 8 | Chinese LLaMA-13B | Cui et al. | 2023/5/15 | 33.3 | 27.3 | 31.6 | 37.2 | 33.6 | 32.8 |
| 9 | MOSS | Fudan | 2023/5/15 | 31.1 | 24 | 28.6 | 36.8 | 31 | 30.3 |
| 10 | Chinese Alpaca-13B | Cui et al. | 2023/5/15 | 26.7 | 27.1 | 26 | 27.2 | 27.8 | 26.4 |
原文连接:C-Eval:热门AI 语言模型的中文水平能力测试
所有媒体,可在保留署名、
原文连接的情况下转载,若非则不得使用我方内容。