PHP四种相似度检测方案+改进计算字符串相似度的函数similar_text()、levenshtein()
- 发表于
- PHP
需求
题库系统中对题目进行重复度检测,把所有重复的题目展示出来。
如何定义重复?
刚开始是按100%重复,才算重复。
现要求,70%的重复,也算重复。
分析
背景知识:题目=题干+选项
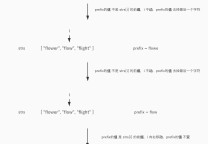
1.100%重复的情况下,只需要,获取题干数组,php获取重复的项,再获取对应的文章id就好了。
2.php如何获取数组中,70%重复的题目id呢?
PHP相似度重复检测函数,网上一般有四种方法
I similar_text()
php内置函数,具体使用方法,请百度,对中文字符串支持不好
II levenshtein()
php内置函数,具体方法,百度
这个好像更快,但是对字符串长度有限制,超过255,就无法检测。报错信息如下:
|
1 2 |
Warning: levenshtein(): Argument string(s) too long in D:\phpstudy_pro\WWW\index.php on line 17 1.0018518518519 |
III 自定义php检测类,不考虑性能,无字符限制,但是中文检测不准
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
<?php class LCS { var $str1; var $str2; var $c = array(); /*返回串一和串二的最长公共子序列*/ function getLCS($str1, $str2, $len1 = 0, $len2 = 0) { $this->str1 = $str1; $this->str2 = $str2; if ($len1 == 0) $len1 = strlen($str1); if ($len2 == 0) $len2 = strlen($str2); $this->initC($len1, $len2); return $this->printLCS($this->c, $len1 - 1, $len2 - 1); } /*返回两个串的相似度*/ function getSimilar($str1, $str2) { $len1 = strlen($str1); $len2 = strlen($str2); $len = strlen($this->getLCS($str1, $str2, $len1, $len2)); return $len * 2 / ($len1 + $len2); } function initC($len1, $len2) { for ($i = 0; $i < $len1; $i++) $this->c[$i][0] = 0; for ($j = 0; $j < $len2; $j++) $this->c[0][$j] = 0; for ($i = 1; $i < $len1; $i++) { for ($j = 1; $j < $len2; $j++) { if ($this->str1[$i] == $this->str2[$j]) { $this->c[$i][$j] = $this->c[$i - 1][$j - 1] + 1; } else if ($this->c[$i - 1][$j] >= $this->c[$i][$j - 1]) { $this->c[$i][$j] = $this->c[$i - 1][$j]; } else { $this->c[$i][$j] = $this->c[$i][$j - 1]; } } } } function printLCS($c, $i, $j) { if ($i == 0 || $j == 0) { if ($this->str1[$i] == $this->str2[$j]) return $this->str2[$j]; else return ""; } if ($this->str1[$i] == $this->str2[$j]) { return $this->printLCS($this->c, $i - 1, $j - 1) . $this->str2[$j]; } else if ($this->c[$i - 1][$j] >= $this->c[$i][$j - 1]) { return $this->printLCS($this->c, $i - 1, $j); } else { return $this->printLCS($this->c, $i, $j - 1); } } } $lcs = new LCS(); $str1 = '我是雷锋123'; $str2 = '我是雷锋abc'; //返回最长公共子序列 $lcs->getLCS($str1, $str2); //返回相似度 echo $lcs->getSimilar($str1, $str2); |
IV 改进型
PHP改进计算字符串相似度的函数similar_text()、levenshtein()
最终选用四的方法中,对leveshtein的改进
优势:1.计算准确 2.打破255的长度限制
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
<?php //拆分字符串 function mbStringToArray($string, $encoding = 'UTF-8') { $arrayResult = array(); while ($iLen = mb_strlen($string, $encoding)) { array_push($arrayResult, mb_substr($string, 0, 1, $encoding)); $string = mb_substr($string, 1, $iLen, $encoding); } return $arrayResult; } //编辑距离 function levenshtein_cn($str1, $str2, $costReplace = 1, $encoding = 'UTF-8') { $count_same_letter = 0; $d = array(); $mb_len1 = mb_strlen($str1, $encoding); $mb_len2 = mb_strlen($str2, $encoding); $mb_str1 = mbStringToArray($str1, $encoding); $mb_str2 = mbStringToArray($str2, $encoding); for ($i1 = 0; $i1 <= $mb_len1; $i1++) { $d[$i1] = array(); $d[$i1][0] = $i1; } for ($i2 = 0; $i2 <= $mb_len2; $i2++) { $d[0][$i2] = $i2; } for ($i1 = 1; $i1 <= $mb_len1; $i1++) { for ($i2 = 1; $i2 <= $mb_len2; $i2++) { // $cost = ($str1[$i1 - 1] == $str2[$i2 - 1]) ? 0 : 1; if ($mb_str1[$i1 - 1] === $mb_str2[$i2 - 1]) { $cost = 0; $count_same_letter++; } else { $cost = $costReplace; //替换 } $d[$i1][$i2] = min( $d[$i1 - 1][$i2] + 1, //插入 $d[$i1][$i2 - 1] + 1, //删除 $d[$i1 - 1][$i2 - 1] + $cost ); } } return $d[$mb_len1][$mb_len2]; //return array('distance' => $d[$mb_len1][$mb_len2], 'count_same_letter' => $count_same_letter); } $str1 = '我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是雷锋123111{dsadas}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}'; $str2 = '我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}我是乔峰abc{[dsds]}'; //计算编辑长度并输出 echo levenshtein_cn($str1, $str2); echo '<br/>'; //获取两者中最长的字符串长度 $len = mb_strlen($str1) >= mb_strlen($str2) ? mb_strlen($str1) : mb_strlen($str2); //计算相似度,并输出 echo 1 - levenshtein_cn($str1, $str2) / $len; |
如何获取题干中,70%重复的元素呢
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<?php $arr = ['是的1111', '我好的很哦', '你好的很呀', '是的1111', '我好的很哦', '你好的很呀', '是的1111', '我好的很哦', '你好的很呀', '是的1111', '我好的很哦', '你好的很呀', '是的1111', '我好的很哦']; echo count($arr); echo '<br/>'; foreach ($arr as $k => $v) { for ($i = 0; $i < count($arr); $i++) { $str1 = $v; $str2 = $arr[$i]; //获取两者中最长的字符串长度 $len = mb_strlen($str1) >= mb_strlen($str2) ? mb_strlen($str1) : mb_strlen($str2); //计算相似度,并输出 echo $k . '和' . $i . '的重复度是' . (1 - levenshtein_cn($str1, $str2) / $len); echo '<br/>'; } } |
s数据量巨大的时候,有什么高效的算法吗
有人跟我遇到了同样的问题-----数据两两比较的高效算法?
好像这里也没人解决掉了,但是需求是一样的。
百度到了js的算法,改了改,就得到了php数组的两两比较算法
https://www.cnblogs.com/cn-oldboy/p/13580690.html
继续有新的问题,题目众多,比如10W条数据
即便是倒三角算法,还是有着很庞大的计算量。
最终得到相似度检测重复度的方案
1.使用改进版的levenshtein_cn()函数
2.分块检测,不同栏目重复度为0
3.分长度检测,元素的长度如果相差20个字符。直接判断重复度为0
4.分题型检测,不用题型,重复度为0
5.使用倒三角,减少对比次数
6.为了获取丰富的文章信息,以便限制对比次数,推荐使用
获取单列或多列字段值:column( )
参考地址:https://www.php.cn/php/php-column-method.html
关于分块检测又思考如下:thinkphp5能不能在循环中,使用db类?
两种方法
1.我们是一次获取所有题干,并带上栏目信息
2.循环所有栏目,在栏目内部,使用db类,获取题干数组,进行对比
听人说,不建议在循环中使用db,多次操作数据库,会增加服务器开销。
那就使用第一种方法吧
继续操作,如何从数据库一次性获取所有文章,然后根据不同的栏目,生成新的数组
答案:过滤+闭包=====https://www.cnblogs.com/cn-oldboy/p/13583868.html
原文连接的情况下转载,若非则不得使用我方内容。