MySQL查询重复数据并列出
| 1 | SELECT FieldName,count(*) AS count FROM TableName GROUP BY FieldName HAVING count> 1; |
大于1条的都列出。
MySQL删除重复记录只保留一条
| 1 2 3 4 | DELETE from TableName WHERE (FieldName) in (SELECT FieldName from (SELECT FieldName FROM TableName GROUP BY FieldName HAVING COUNT(*)>1) s1) AND id NOT in (SELECT id from (SELECT id FROM TableName GROUP BY FieldName HAVING COUNT(*)>1) s2); |
FieldName为字段,TableName是表名
ThinkPHP5去重distinct和group
distinct去重
distinct
方法用于返回唯一不同的值,例如数据库表中有以下数据
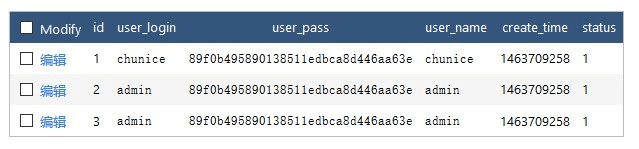
以下代码会返回
user_login
字段不同的数据
| 1 | Db::table('think_user')->distinct(true)->field('user_login')->select(); |
生成的SQL语句是:
SELECT DISTINCT user_login FROM think_user
返回以下数组
| 1 2 3 4 5 6 7 8 | array(2) { [0] => array(1) { ["user_login"] => string(7) "chunice" } [1] => array(1) { ["user_login"] => string(5) "admin" } } |
distinct
方法的参数是一个布尔值。
group去重
GROUP
方法通常用于结合合计函数,根据一个或多个列对结果集进行分组 。
group
方法只有一个参数,并且只能使用字符串。
例如,我们都查询结果按照用户id进行分组统计:
| 1 2 3 4 | Db::table('think_user') ->field('user_id,username,max(score)') ->group('user_id') ->select(); |
生成的SQL语句是:
| 1 | SELECT user_id,username,max(score) FROM think_score GROUP BY user_id |
也支持对多个字段进行分组,例如:
| 1 2 3 4 | Db::table('think_user') ->field('user_id,test_time,username,max(score)') ->group('user_id,test_time') ->select(); |
生成的SQL语句是:
| 1 | SELECT user_id,test_time,username,max(score) FROM think_user GROUP BY user_id,test_time |
总结
- SQL操作最直接,不讲。
- 利用distinct去重、简单易用,但只能对于单一字段去重,并且最终的结果也仅为去重的字段。
- 利用group去重,最终的显示结果为所有字段,且对单一字段进行了去重操作,但最终显示结果除去去重字段外,按照第一个字段进行排序。
原文连接:MySQL/ThinkPHP5去重,查询重复数据并列出,删除重复数据只保留一条 所有媒体,可在保留署名、
原文连接
的情况下转载,若非则不得使用我方内容。