一个绕过Google谷歌验证码(reCAPTCHA)的方法
- 发表于
- 周边
在很多反向代理场景,或是爬虫中我们都会使用脚本程序提取搜索结果而不是使用谷歌镜像。但谷歌搜索(google)的反爬虫及异常流量标准会给我们带来很多麻烦,一旦出现验证码reCAPTCHA,就基本中断了数据。今天体验盒子介绍一个方法可以绕开谷歌搜索永远不出现验证码的方案。
绕开谷歌搜索验证码reCAPTCHA
Facebook 有一个调试工具。有趣的是,Google不会限制此调试程序发出的请求(列入白名单?),因此可以用来绕开Google搜索结果而不会被验证码阻止。由于涉及facebook,每个请求都必须向库提供一个 facebook 会话 Cookie。
方案已经有了,下面只要实现它就行了,这里分享一个现成的谷歌搜索结果提取脚本,并且就是基于该方法绕开验证码的。
goop
谷歌搜索脚本,基于Python,
安装
pip install goop或
git clone https://github.com/s0md3v/goop.git使用示例
from goop import goop
page_1 = goop.search('red shoes', '<your facebook cookie>')
page_2 = goop.search('red_shoes', '<your facebook cookie>', page='1')
include_omitted_results = goop.search('red_shoes', '<your facebook cookie>', page='8', full=True)返回的数据结构
{
"0": {
"url": "https://example.com",
"text": "Example webpage",
"summary": "This is an example webpage whose aim is to demonstrate the usage of ..."
},
"1": {
...cli.py通过使用以下命令从终端执行谷歌搜索来演示使用情况
python cli.py <query> <number_of_pages>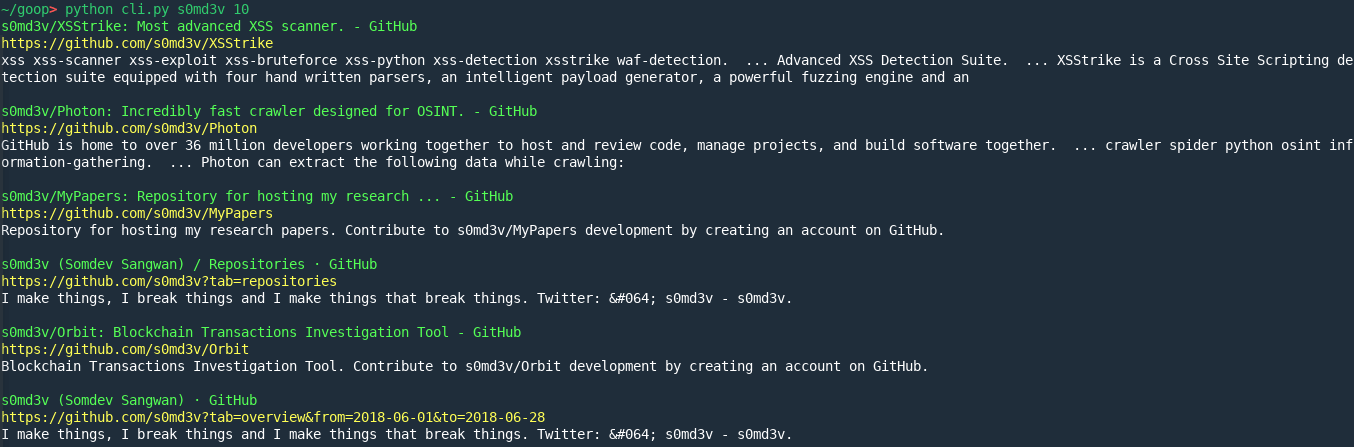
至此,已经完整走过一遍绕开谷歌搜索结果验证码的流程,你可以将该方法融入到任何项目中。
但也要注意,故意绕开谷歌搜索验证码及使用facebook调试方法进行目的的操作都是不可取及不长久的。仅限用于概念验证而非非法使用。
原文连接:一个绕过Google谷歌验证码(reCAPTCHA)的方法
所有媒体,可在保留署名、
原文连接的情况下转载,若非则不得使用我方内容。