RGPerson – 随机身份信息生成脚本
- 发表于
- 安全工具
RGPerson 随机身份信息
做测试的时候经常遇到一些模拟注册的业务场景,要填写的东西很多,一般都是临时去百度信息,这样很繁琐所以决定造轮子撸了个随机身份生成的,如果是非测试场景,可参考社会工程学相关。
该脚本生成信息:姓名\年龄\性别\身份证\手机号
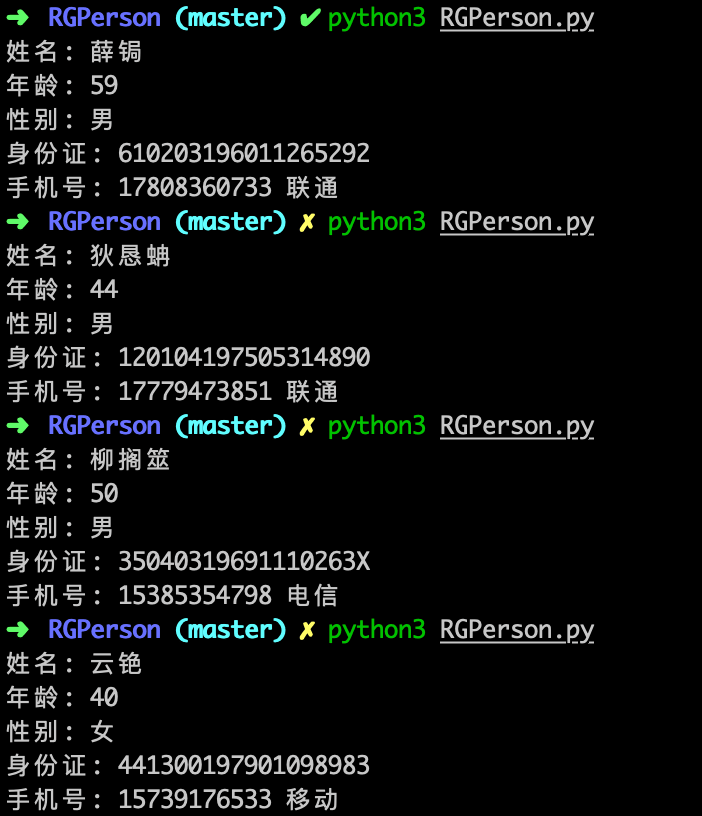
生成的信息都是模拟的假数据,仅限用于业务测试使用。
本编写原理
脚本的三大函数: genMobile()、genIdCard()、genName()
genMobile() 为随机生成手机号的函数
genName() 为随机生成姓名的函数
genIdCard() 为随机生成身份证的函数
genMobile()
随机生成手机号:需要知道国内手机号的构成
1.长度为十一位
2.前三位表示运营商
现在我们只需要做到收集手机号号段的前三位以及对应的运营商:
|
1 |
prelist = {"133":"电信","149":"电信","153":"电信","173":"电信","177":"电信","180":"电信","181":"电信","189":"电信","199":"电信","130":"联通","131":"联通","132":"联通","145":"联通","155":"联通","156":"联通","166":"联通","171":"联通","175":"联通","176":"联通","185":"联通","186":"联通","166":"联通","134":"移动","135":"移动","136":"移动","137":"移动","138":"移动","139":"移动","147":"移动","150":"移动","151":"移动","152":"移动","157":"移动","158":"移动","159":"移动","172":"移动","178":"移动","182":"移动","183":"移动","184":"移动","187":"移动","188":"移动","198":"移动"} |
获取该数组的长度:len(prelist) -> 42
随机生成下标获取三位数:prelist.keys()[random.randint(0,41)]
然后再随机填补后8位即可:
|
1 2 3 4 5 6 |
def genMobile(): prelist = {"133":"电信","149":"电信","153":"电信","173":"电信","177":"电信","180":"电信","181":"电信","189":"电信","199":"电信","130":"联通","131":"联通","132":"联通","145":"联通","155":"联通","156":"联通","166":"联通","171":"联通","175":"联通","176":"联通","185":"联通","186":"联通","166":"联通","134":"移动","135":"移动","136":"移动","137":"移动","138":"移动","139":"移动","147":"移动","150":"移动","151":"移动","152":"移动","157":"移动","158":"移动","159":"移动","172":"移动","178":"移动","182":"移动","183":"移动","184":"移动","187":"移动","188":"移动","198":"移动"} three = list(prelist.keys())[random.randint(0,len(prelist)-1)] mobile = three + "".join(random.choice("0123456789") for i in range(8)) op = prelist[three] return {mobile:op} |
genName()
随机生成姓名:中文名字通常为2、3位汉字组成
1.收集常用的姓氏随机取其一个:
|
1 2 3 4 5 6 7 8 9 10 11 |
def first_name(): first_name_list = ['赵', '钱', '孙', '李', '周', '吴', '郑', '王', '冯', '陈', '褚', '卫', '蒋', '沈', '韩', '杨', '朱', '秦', '尤', '许', '何', '吕', '施', '张', '孔', '曹', '严', '华', '金', '魏', '陶', '姜', '戚', '谢', '邹', '喻', '柏', '水', '窦', '章', '云', '苏', '潘', '葛', '奚', '范', '彭', '郎', '鲁', '韦', '昌', '马', '苗', '凤', '花', '方', '俞', '任', '袁', '柳', '酆', '鲍', '史', '唐', '费', '廉', '岑', '薛', '雷', '贺', '倪', '汤', '滕', '殷', '罗', '毕', '郝', '邬', '安', '常', '乐', '于', '时', '傅', '皮', '卞', '齐', '康', '伍', '余', '元', '卜', '顾', '孟', '平', '黄', '和', '穆', '萧', '尹', '姚', '邵', '堪', '汪', '祁', '毛', '禹', '狄', '米', '贝', '明', '臧', '计', '伏', '成', '戴', '谈', '宋', '茅', '庞', '熊', '纪', '舒', '屈', '项', '祝', '董', '梁'] n = random.randint(0, len(first_name_list) - 1) f_name = first_name_list[n] return f_name |
2.这里一开始想搜罗常用的名字,但参考了其他师傅的代码发现随机生成中文字符更好一点:
|
1 2 3 4 5 6 |
def GBK2312(): head = random.randint(0xb0, 0xf7) body = random.randint(0xa1, 0xf9) val = f'{head:x}{body:x}' st = bytes.fromhex(val).decode('gb2312') return st |
3.随机生成名字的第二个字:(这里用一个list做一个空值,随机取生成的汉字或空值,用于成为随机生成2位名字或3位名字)
|
1 2 3 4 5 |
def second_name(): second_name_list = [GBK2312(), ''] n = random.randint(0, 1) s_name = second_name_list[n] return s_name |
4.随机生成名字的最后一个字:(用于满足三个汉字的名字)
|
1 2 |
def last_name(): return GBK2312() |
5.拼接
|
1 2 |
def last_name(): return GBK2312() |
genIdCard()
随机生成身份证:公民身份号码是由17位数字码和1位校验码组成
18位数字组合的方式是:
| 1 1 0 1 0 2 | Y Y Y Y M M D D | 8 8 | 8 | X |
|---|---|---|---|---|
| 区域码(6位) | 出生日期码(8位) | 顺序码(2位) | 性别码(1位) | 校验码(1位) |
- 6位区域码爬取http://www.360doc.com/content/12/1010/21/156610_240728293.shtml,存到了
districtcode.py
区域码 指的是公民常住户口所在县(市、镇、区)的行政区划代码,如110102是北京市-西城区。但港澳台地区居民的身份号码只精确到省级。
- 8位出生日期码,具体Python代码如下:
|
1 2 3 4 5 |
age = random.randint(16,60) #可调整生成的年龄范围(身份证),这边是16-60岁 y = date.today().year - age #生成的年份 m = date(y, 1, 1) #生成的月份,初始值为1月1日 d = timedelta(days=random.randint(0, 364)) #随机生成的天数 datestring = str(m + d) #加天数得到最终值 |
出生日期码 表示公民出生的公历年(4位)、月(2位)、日(2位)。
- 2位顺序码
顺序码 表示在同一区域码所标识的区域范围内,对同年、同月、同日出生的人编定的顺序号。
- 1位性别码
性别码 奇数表示男性,偶数表示女性。
- 最后一位是校验码,这里采用的是ISO 7064:1983,MOD 11-2校验码系统。校验码为一位数,但如果最后采用校验码系统计算的校验码是“10”,碍于身份证号码为18位的规定,则以“X”代替校验码“10”。
最难的还是校验码的算法,参考师傅的解说:
- 将前面的身份证号码17位数分别乘以不同的系数。从第一位到第十七位的系数分别为:7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2
- 将这17位数字和系数相乘的结果相加。
- 用加出来和除以11,得余数
- 余数只可能是0 1 2 3 4 5 6 7 8 9 10这11个数字,其分别对应的最后一位身份证的号码为1 0 X 9 8 7 6 5 4 3 2。
- 通过上面得知如果余数是2,就会在身份证的第18位数字上出现罗马数字的Ⅹ,如果余数是10,身份证的最后一位号码就是2。
测试代码如下,取了几个真实的身份证号码发现可用:
|
1 2 3 4 5 6 7 8 |
def test(id_num): id_code_list = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2] check_code_list = [1, 0, 'X', 9, 8, 7, 6, 5, 4, 3, 2] a = 0 print(len(id_num)) for i in range(17): a = a + (int(id_num[i]) * id_code_list[int(i)]) print(check_code_list[a % 11]) |
整合一下(Copy)就变成了如下完整的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def genIdCard(age,gender): area_code = ('%s' % random.choice(list(area_dict.keys()))) id_code_list = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2] check_code_list = [1, 0, 'X', 9, 8, 7, 6, 5, 4, 3, 2] if str(area_code) not in area_dict.keys(): return None datestring = str(date(date.today().year - age, 1, 1) + timedelta(days=random.randint(0, 364))).replace("-", "") rd = random.randint(0, 999) if gender == 0: gender_num = rd if rd % 2 == 0 else rd + 1 else: gender_num = rd if rd % 2 == 1 else rd - 1 result = str(area_code) + datestring + str(gender_num).zfill(3) b = result + str(check_code_list[sum([a * b for a, b in zip(id_code_list, [int(a) for a in result])]) % 11]) return b |
原文连接的情况下转载,若非则不得使用我方内容。